robots.txt Generator
Generate robots.txt. Disallow paths, sitemap URL. Configure crawler rules.
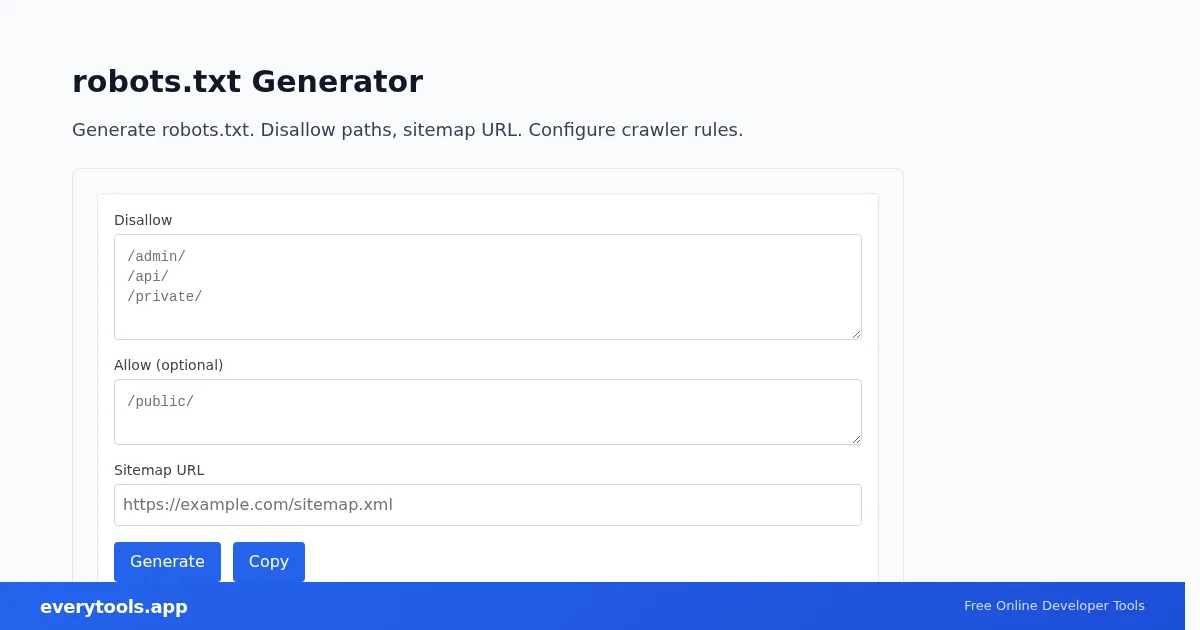
Generate robots.txt online
Draft crawler rules and point to your XML sitemap. Common need: “robots.txt generator” with Disallow paths for staging or admin areas.
How robots.txt Generator Works
Paste or enter your input in the field above. Most tools update in real time. Click the Copy button to copy the output. All processing happens in your browser—your data never leaves your device unless the tool explicitly uses a server feature (such as URL shortening or bcrypt hashing).
This tool is part of the SEO Tools category. Check similar tools below. All everytools are free, no signup required. Works on desktop and mobile.
Common Use Cases
- Block non-production hosts from indexing
- Expose sitemap location to crawlers
- Template starter robots.txt for new projects
You might also like
Other SEO Tools
Meta Tag Generator
Generate SEO meta tags: title, description, keywords. Includes character count for Google (title 30-60, description 50-160).
JSON-LD Schema Generator
Generate JSON-LD structured data. WebSite, Organization, Article, Product schemas. Copy-ready for Schema.org.
Open Graph Meta Generator
Generate Open Graph and Twitter Card meta tags. og:title, og:description, og:image for social sharing.
XML Sitemap Generator
Generate XML sitemap from URL list. One URL per line. For search engine submission.
Meta Tag Analyzer
Analyze meta title and description. Character count, word count. SEO recommendations for length.
Canonical URL Generator
Generate canonical URL from input. Normalize, remove tracking params, set protocol. For SEO and deduplication.
Frequently Asked Questions
- Does robots.txt block hackers?
- No. It is a polite signal to crawlers, not authentication. Sensitive areas need server-side protection.
- Include sitemap in robots.txt?
- You can reference your sitemap URL here; many sites do for discoverability.